Originally published on Medium: Apache Helix: The Distributed System’s Orchestra Conductor
 Image by DALLE-2 (credit to human artists)
Image by DALLE-2 (credit to human artists)
Distributed systems are mainstream in software workflows these days. These are the systems where servers communicate with the client and each other (usually through gossip and consensus protocols). Distributed systems help solve a major problem where you must spread out a common task across multiple servers for performance and availability.
You also need to ensure consistency and fault tolerance in such systems. Otherwise, either task will return an output that results from a data snapshot at two different points in time or an incomplete result because some node failed during processing.
Writing a Distributed System Is Not Easy
If only it were as easy as implementing API calls between servers. Running and maintaining a distributed system is not a simple task in itself.
As you can imagine, writing a new one is much more challenging.
Take CassandraDB as an example. The basic function of the DB is to process a CQL query, gather data from multiple nodes and return the aggregated response.
However, in the background, you have to communicate properly between all the nodes using Gossip, reach a leadership consensus via Paxos, and ensure it is fault-tolerant by distributing SSTables correctly. All of this has to be done while supporting the addition and removing existing nodes while providing the same query performance.
What if you allowed a distributed system to separate its supervision logic from its business logic? That way, the developers of a distributed DB similar to Cassandra can focus only on the query execution part while the fault tolerance, replication, and token assignment are taken care of by this new entity.
Enter Apache Helix
Apache Helix allows developers to express your complex distributed system as a simple finite-state machine. All the management operations are then represented as transitions in this state machine.
This is great because the general view is that a cluster’s operations differ so much from each system to the next that creating a generic framework is impossible. By using Helix, developers can focus on the core functionalities of their systems and let Helix take care of cluster management.
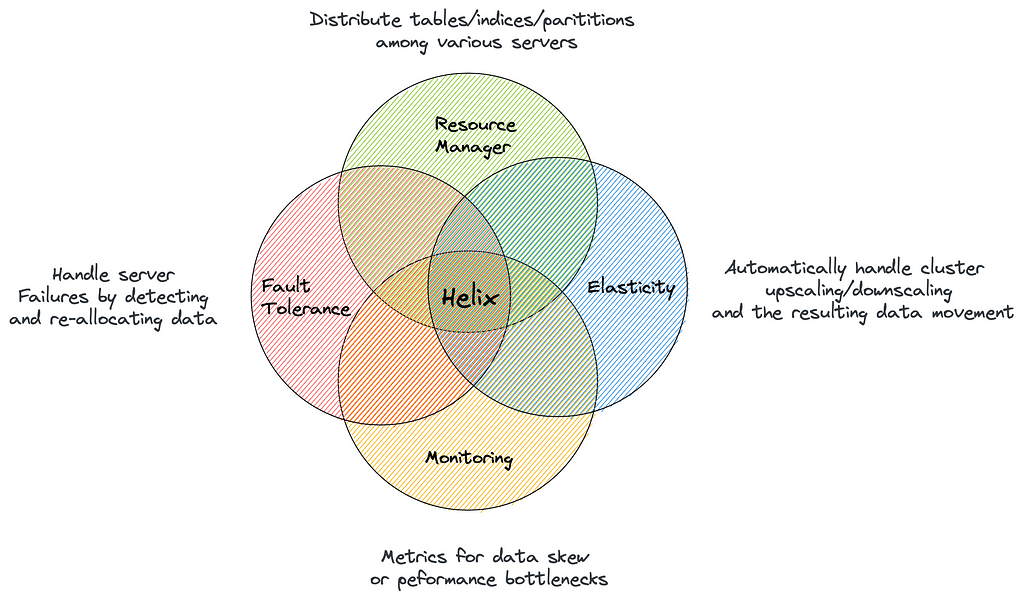 image by author
image by author
Wait, a Distributed System Is a State Machine?
If you don’t know about state machines, it’s a model that can represent a system in a fixed number of states. It also models what transitions are valid from one state to another.
Let’s take the example of the popular real-time event-processing framework Apache Kafka. A Kafka cluster consists of multiple topics. Each topic consists of multiple partitions.
For a topic partition, Apache Kafka needs to ensure the following:
- There is always one leader. The leader is the only one that can accept the writes.
- There are N replicas of the partition where the user can decide N.
- The replicas should be distributed evenly among M server nodes for a fault-tolerant setup.
- Only replicas in sync with the leader can be promoted to a leader if it crashes.
Helix can take care of all this with the following state machine:
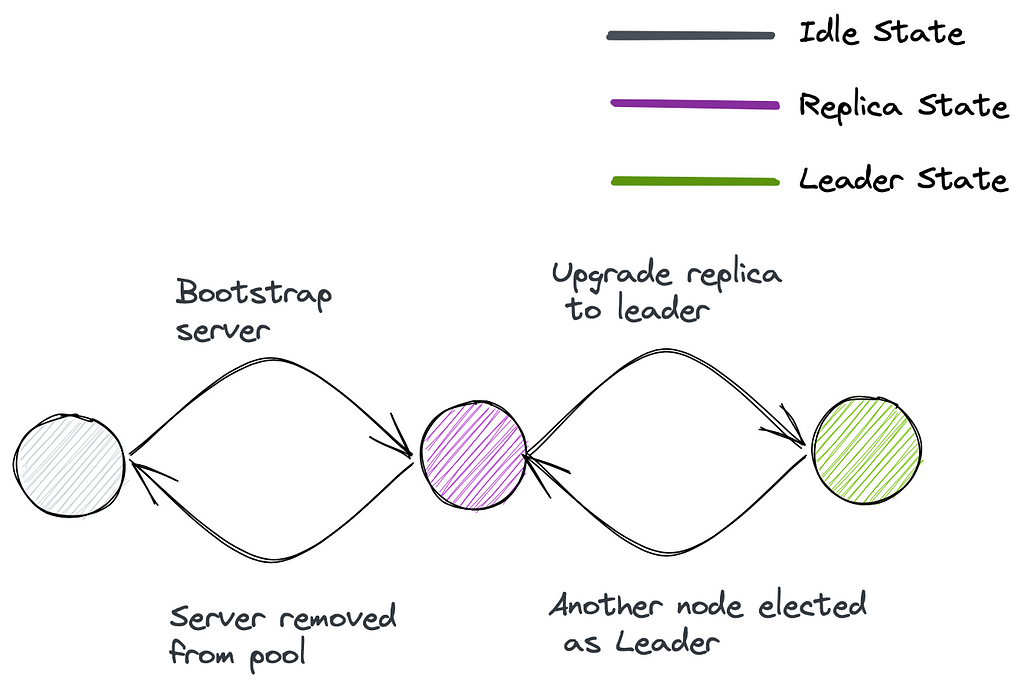 image by author
image by author
This allows Kafka-like systems to focus only on reading/writing data from the partition logs and other admin operations such as adding/deleting topics, managing offsets, and so on.
Let’s take another example of Apache Pinot.
Pinot has multiple tables, each composed of small segment files. The analogy would be a single Cassandra Table comprised of small SSTable files.
For a particular segment, Pinot has the following constraints:
- There should be N replicas of the segment where the user can configure N
- There can only be one consuming segment for each table. All replicas of that segment should be in a consuming state as well.
- The rest of the segment should be in an online state, i.e., ready-to-serve queries.
- In case M new nodes are added, the new segments should also be distributed evenly across these nodes.
- A segment and replicas should be dropped in case users reach or manually delete a retention duration.
This can be represented with the following state machine:
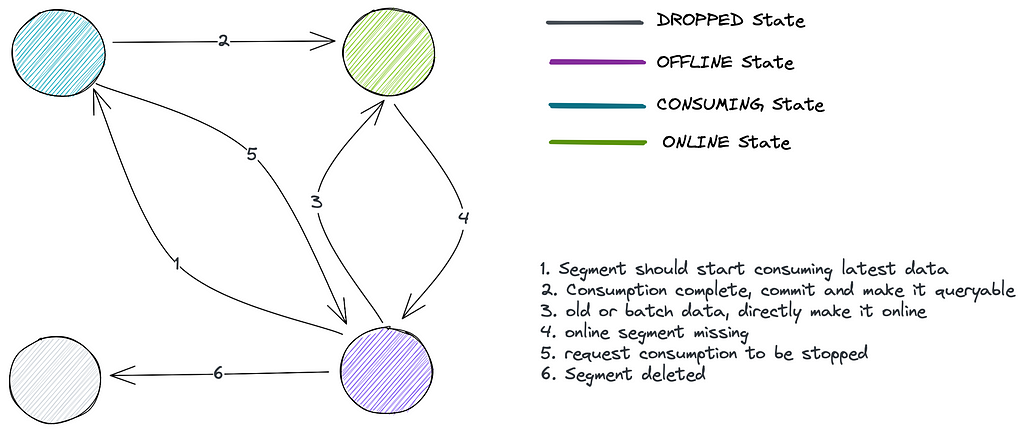 image by author
image by author
So, Where Does Helix Come Into the Picture?
The user will upload these state machines (in a form of config) to Helix. Helix then keeps track of all the nodes in the cluster through inbuilt monitoring.
It also keeps track of the state of each partition in each node. Helix then creates a map of what the ideal state of each partition should be. If the partition’s actual and ideal state does not match, Helix will queue up State transitions.
The attractiveness of Helix though is due to the following:
- It can do multiple state transitions in parallel.
- Take care of coordination between multiple servers. For example, if a serverB is made leader instead of serverA, remove the serverB from the leadership before adding serverA.
- It can decide the order of state transitions even when done in parallel to not violate the constraints. For example, upgrading a new server with no data to the leader OR assigning some replica partition to a node that has the leader as well.
- Decide the priority of the transitions (which can be modified using a config). For example, if a leader fails at the same time some new nodes are added to the cluster, the transition from replica to leader status should take higher priority than the transition from idle to replica state.
- Modify the ideal state based on cluster monitoring. For example, where to move the partitions residing on the failed node if a node goes down?
Here’s how the state machine for Kafka can be implemented via Helix:
StateModelDefinition.Builder builder = new StateModelDefinition.Builder("your-state-model");
builder.initialState("IDLE");
builder.addState("IDLE");
builder.addState("REPLICA");
builder.addState("LEADER");
// Set the initial state when the node starts
// Add transitions between the states.
builder.addTransition("IDLE", "REPLICA");
builder.addTransition("REPLICA", "LEADER");
builder.addTransition("REPLICA", "IDLE");
builder.addTransition("LEADER", "REPLICA");
// Set constraint that there can only be 1 leader at a time
builder.dynamicUpperBound("LEADER", "1");
// Set transition priority
// the first inserted gets the top most priority.
List<String> stateTransitionPriorityList = new ArrayList<String>();
stateTransitionPriorityList.add("REPLICA-LEADER");
stateTransitionPriorityList.add("IDLE-REPLICA");
stateTransitionPriorityList.add("REPLICA-IDLE");
stateTransitionPriorityList.add("LEADER-REPLICA");
record.setListField(StateModelDefinitionProperty.STATE\_TRANSITION\_PRIORITYLIST.toString(),
stateTransitionPriorityList); Assigning State to Each Partition
Internally, Helix uses a modified version of the RUSH algorithm to decide the final state and then uses a greedy approach to figure out valid transactions and schedule them. By greedy approach, I mean the transactions are appended to a list of pending transactions until we get two transactions that cannot be done in parallel.
Helix also allows users to plugin any other placement strategy, e.g., ConsistentHashing depending on the use case.
How Is Helix Agnostic of Core System Logic?
It should know how to deal with data movement across servers, how to read data in each partition, and so on, right?
Well, I never said Helix performs the state transition. Helix issues the request with the transition that needs to be performed to the server that needs to perform it. Currently, it is done using Apache Zookeeper as a message queue.
 Using Zookeeper as MQ to communicate transition
Using Zookeeper as MQ to communicate transition
// Helix leader, running on a controller node
state.setPartitionState(partitionName, serverName, “ONLINE”);
// Helix Listener, running inside each server
@Transition(from = “OFFLINE”, to = “ONLINE”)
public void onBecomeOnlineFromOffline(Message message, NotificationContext context) {
String partitionName = message.getPartitionName();
// Logic to add partition
// Create partition files
// add partition to queryable list
}
Each server has a listener which keeps track of new messages in the queue. The listener has the business logic on what to do when asked to move from State A to State B. For example, if it needs to copy data from S3 for bootstrapping or start accepting writes since it has been promoted to leader.
The server doesn’t need to care about what other servers are doing, e.g., who is the leader, if some other server already has the same data, and so on. It simply performs what it’s asked to do and then updates the actual state of the partition. If it cannot complete the task, it reverts to an error, and Helix can take appropriate follow-up action.
Conclusion
Although Apache Helix can help you simplify cluster management to an amazing degree, it still lacks some features:
- Helix can’t take heterogeneous servers into account while calculating the final state. For example, you should be able to schedule twice as many partitions on a node that is 2X larger than the rest of the nodes.
- Helix can’t properly account for replication in a cluster distributed across multiple AZs. In such cases, you must ensure the replicas are present in different AZs.
You can use the following references to learn more about Helix:
- Helix repository — https://github.com/apache/helix/tree/master
- Helix whitepaper — https://dl.acm.org/doi/10.1145/2391229.2391248
- Helix in Apache Pinot — https://docs.pinot.apache.org/basics/architecture